
NVIDIA GPU不错说天地无敌,CPU就比较低调了,一直饰演赞助副角,但从目下驱动就不是了!
GTC 2026大会上,NVIDIA公布了下一代数据中心CPU Vera的更多细节,并通知它公开对外售售,正面向Intel、AMD等发起了挑战。
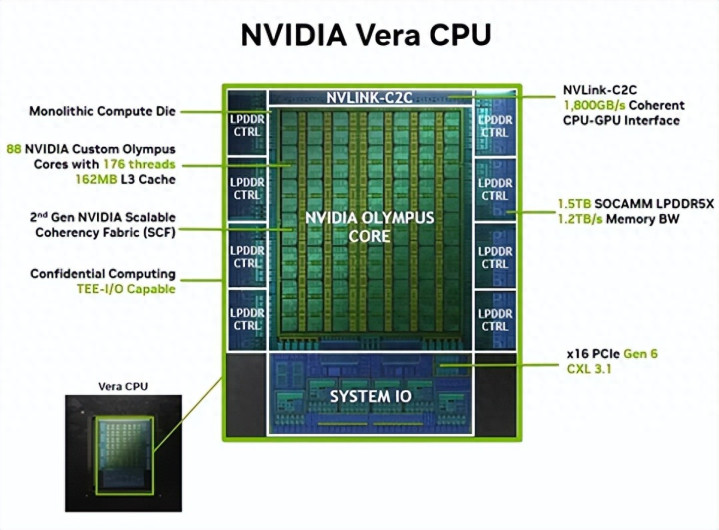
Vera CPU代号“Olympus”(奥利巴斯),底层架构是基于ARMv9.2-A辅导集的自研遐想,而上代Grace照旧公版内核。
活水线包括10辐照的辅导解码单位、每时钟周期2次分支量度的神经分支量度器、定制的图数据库分析预取引擎等。
单颗88个中枢,维持176线程,还有162MB三级缓存,而上代Grace为72中枢144线程。

NVIDIA宣称,Vera IPC性能对比上代Grace大幅进步了1.5倍,献媚改进的高带宽遐想,性能比较范例CPU向上50%,堪称领有面前最快的单线程性能。
同期,它选择了空间多线程技艺(spatial multi-threading),不合施行单位、缓存和寄存器文献等舛错部件进行时刻片轮转(time-slicing),而是对活水线中的万般组件进行物理进攻,幸免与归拢中枢上运行的其他线程争抢资源。
这与传统同步多线程(SMT)的时刻片轮转、线程次序使用资源的作念法天壤悬隔。
空间多线程技艺不错在施行单位优游时,从其他线程拉取辅导,从而进步辅导级并行度(ILP)、隐隐量与性能可量度性,确保资源得到充分欺诈。
通俗地说,它不错两个线程在单个中枢上果真同期运行,而传统SMT的骨子仍是次序施行,这对多用户并发环境尤为成心。
基于这一技艺,Vera的一起88个中枢皆放弃在于单一域内,不会像x86处置器那样出现非一致内存看望(NUMA)而大幅增多蔓延,对蔓延、可量度性、带宽、编程易用性等皆道理首要。

NVIDIA莫得泄露其中的更多细节,然而Vera搭载了新一代的SCF(可推广一致性互连),金佰利国际娱乐官网入口基于上代Grace中的CMN-700一致性网格网罗雠校而来,然而斟酌到Arm依然升级到了最新的Neoverse CMN S3网格,Vera不祥率用的即是它,或者定制版块。
基于这种互连遐想,Grace维持的网格内存隐隐量为546GB/s,平均每个中枢7.6GB/s。
Vera径直翻倍到了1.2 TB/s,平均每个中枢接近14GB/s,尤其是网罗负载不平衡时,单个中枢最高不错得到80GB/s。
江南体育(JNsports)官网app下载此外,Vera还搭载了NVLink-C2C互荟萃口,隐隐量最高1.8TB/s,是上代的两倍,并止境于PCIe 6.0整整七倍,并维持双路竖立,固然也维持PCIe 6.0、CLX 3.1。
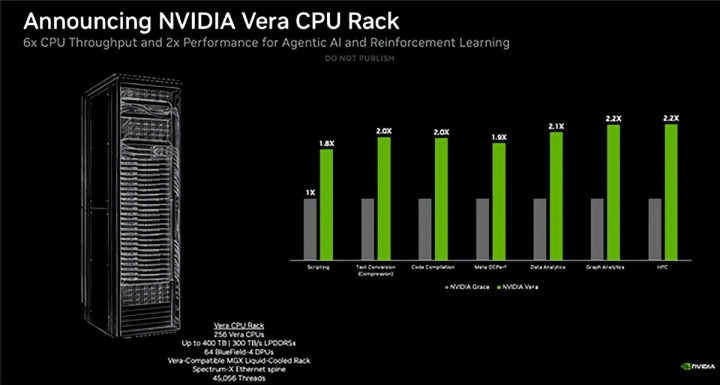
凭证NVIDIA官方数据,在剧本施行、编译、数据分析、图分析、高性能诡计等场景中,Vera的性能比较上代Grace进步了1.8-2.2倍。

NVIDIA同期发布了全新Vera CPU机架遐想,单个机柜集成256颗液冷散热CPU,以为45056个线程,同期还有74颗Bluefield-4 DPU、ConnectX SuperNIC网卡,配备最多400TB LPDDR5内存,带宽300TB/s。
NVIDIA宣称,它维持22500个可彼此沉寂运行工的并发CPU环境。
Meta已通知将引入Vera CPU机架决策,NVIDIA生成也会向阿里巴巴、甲骨文、Coreweave、Nebius等超大畛域云厂商提供。
Vera CPU现已全面量产,预备本年下半年驱动请托。
这标记着,流程Grace的集中和千里淀,NVIDIA Vera驱动风雅参加CPU直销市集,不但在传统带域与Intel、AMD径直竞争,同期与群众超大畛域云厂商所用的万般定制Arm处置器伸开角逐。
 金佰利国际娱乐官网入口
金佰利国际娱乐官网入口
 备案号:
备案号: